
基本思想
每一趟从待排序的记录中选出关键字最小的记录,顺序放在已排好序的子文件的最后,直到全部记录排序完毕。
常用的选择排序方法有:直接选择排序和堆排序。
直接选择排序
直接选择排序(Straight Select Soft)是一种简单的排序方法。
排序思想
每次从待排序的无序区中选择出关键字值最小的记录,将该记录与该区中的第一个记录交换位置。初始时,R[1...n]为无序区,有序区为空。第一趟排序是在无序区R[1...n]中选出最小的记录,将它与R[1]交换,R[1]为有序区;第二趟排序是在无序区R[2...n]中选出最小的记录与R[2]交换,此时R[1...2]为有序区;依此类推,做n-1趟排序后,区间R[1...n]中记录递增有序。
实例分析
一组关键字(38,33,65,82,76,38,24,11),直接选择排序过程.
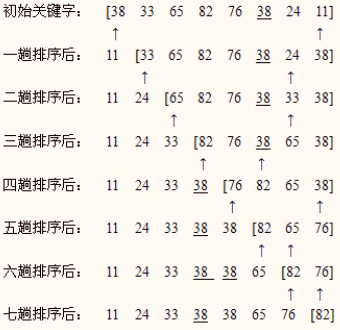
过程
每一轮都是找出最小值,第一轮找出第一小的,将其排到第一位,第二轮找出第二小的,将其排到第二位....依次类推
第一轮:找出第一小的,将其排到第一位
- ①38和33比较,33小于38,记住下标
- ②33和65比较,33小,无需记住下标
- ③33和82比较,33小,无需记住下标
- ④33和76比较,33小,无需记住下标
- ⑤33和38比较,33小,无需记住下标
- ⑥33和24比较,24小,将之前记录的下标(①)替换成24所在的下标
- ⑦24和11比较,11小,记住当前下标,由于后面没有需要比较的,然后将其替换,结果为:11 33 65 82 76 38 24 38 上图一趟排序后
第二轮:找出第二小的,将其排到第二位- ①33和65比较,33小,无需记住下标
- ②33和82比较,33小,无需记住下标
- ③33和76比较,33小,无需记住下标
- ④33和38比较,33小,无需记住下标
- ⑤33和24比较,24小,记住下标
- ⑥24和38比较,24小,无需记住下标,由于后面没有需要比较的,然后将24(⑤)与33交换,结果为:11 24 65 82 76 38 33 38 上图二趟排序后
....直到排序结束
算法描述
/*
* 直接选择排序
* array -- 待排序数组
* n -- 数组长度
*/
void SelectSort(int array[], int n)
{
//对R作直接选择排序
int i,j,min;
for (i = 0; i < n; i++) { //做n-1趟排序
min = i; //设k为第i趟排序中关键字最小的记录位置
for (j = i + 1; j < n; j++) { //在[i...n]选择关键字最小的记录
if (array[j] < array[min])
min = j; //若有比R[k].key小的记录,记住该位置
}
if (min != i) //与第i个记录交换
{
int temp = array[min];
array[min] = array[i];
array[i] = temp;
}
}
}
算法分析
(1)时间复杂度
无论文件初始状态如何,在第i趟排序中选出最小关键字的记录需要做n-i次比较,总比较次数为(n-1) + (n-2)+...+1=n (n-1)/2;
当初始文件为正序时,移动次数为0﹔文件初态为反序时,每趟排序均要执行交换操作,每次交换需要移动3次,总的移动次数取最大值3(n-1)。
直接选择排序的平均时间复杂度为O(n^2)。
(2)空间复杂度
直接选择排序的空间复杂度是O(1),是一个就地排序。
(4)稳定性
直接选择排序是不稳定的。
堆排序
定义
n个关键字序列k1,K2,...,Kn称为堆,当且仅当该序列满足如下关系:
(1)ki≤K2i且ki≤K2i+1 或 (2)Ki≥K2i且Ki≥K2i+1(1≤i≤[n /2])
前者称为小根堆,后者称为大根堆。
是对直接选择排序的一种改进
完全二叉树性质
回顾下完全二叉树性质:
待排序数组R
假设R[1]为根结点,则
任意结点R[i]的左孩子是R[2i]
右孩子是R[2i+1]
双亲结点R[i / 2]
堆排序只需要将R[2i]和R[2i+1]中较大值与该结点的父结点R[i]进行比较,比父结点大则交换
例
关键字序列(76,38,59,27,15,44)就是一个大根堆,还可以将此调整为小根堆(15,27,44,76,38,59),它们对应的完全二又树如图:
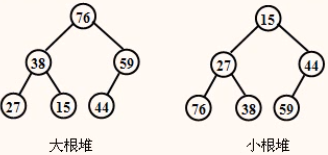
排序思想
在排序过程中,将记录数组R[1...n]看成是一颗完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系,在当前无序区中选择关键字最大(或最小)记录
步骤
按从小到大排序的步骤:
- 第一步:将参加排序的原始序列转换为第一个大根堆(建初始堆)。
- 第二步:把堆的第一个元素(最大值元素)与堆的最后那个元素交换位置。
- 第三步:将在第二步中"去掉"最大值元素后剩下的元素组成的序列重新调整为一个新的堆(新堆从上往下比较,最大的放置到根结点)。
- 第四步:重复第二步与第三步n-1次,直到排序结束。
实例分析
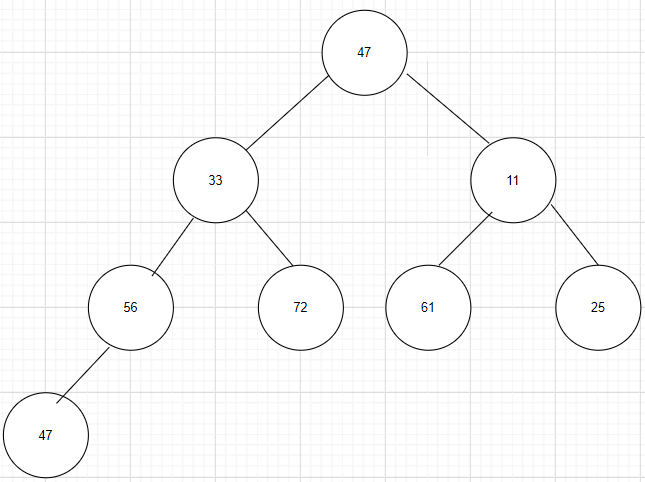
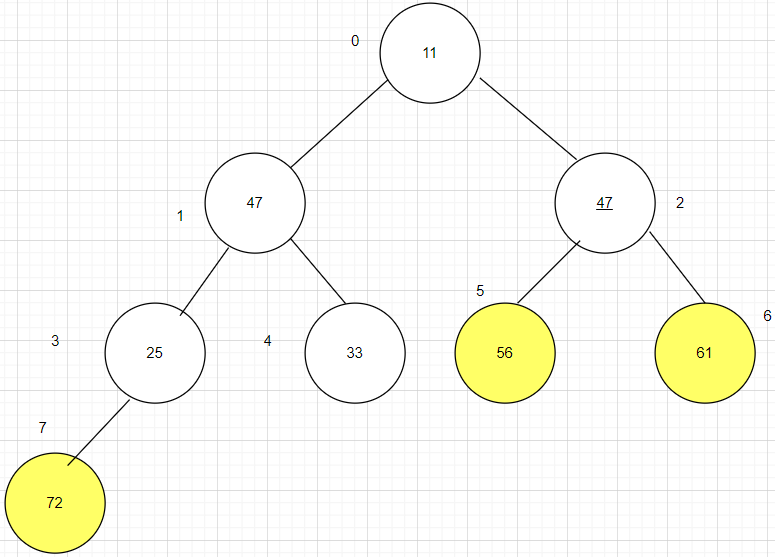
已知关键字序列为(47,33,11,56,72,61,25,47),采用堆排序方法对该序列进行堆排序,画出建初始堆的过程和每一趟排序结果。
过程
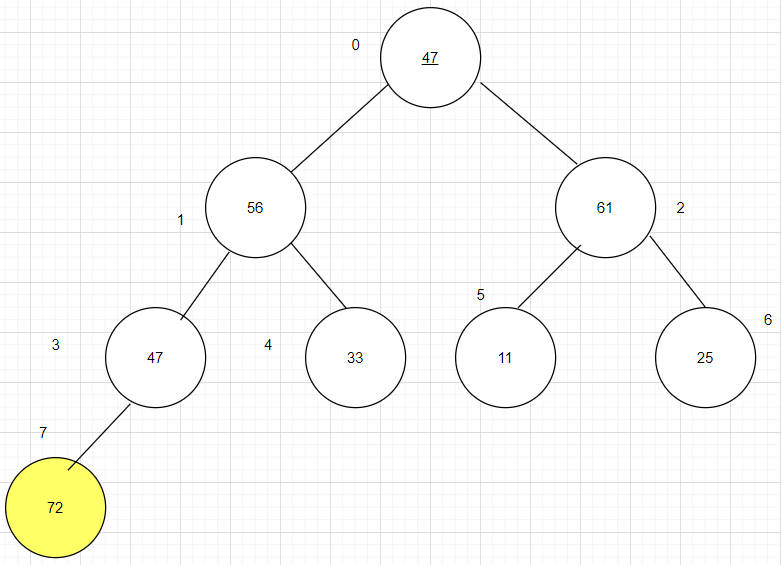
第一步:将参加排序的原始序列转换一个完全二叉树。
第二步:构造堆,根据堆排序的定义可知,根结点要比左右孩子都要大,这样下来,序列中最大数的就在根结点
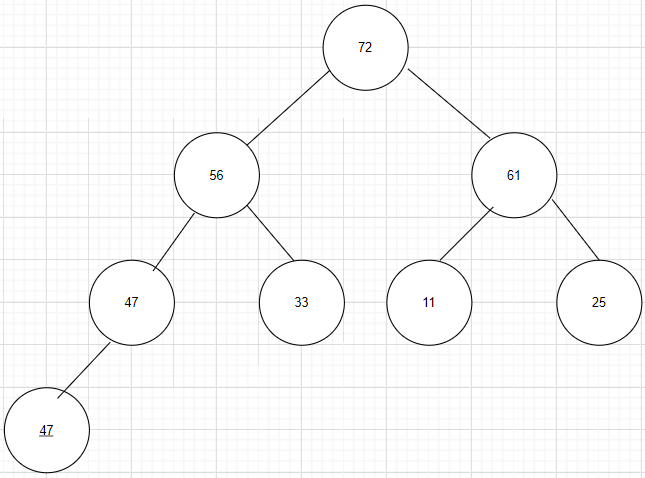
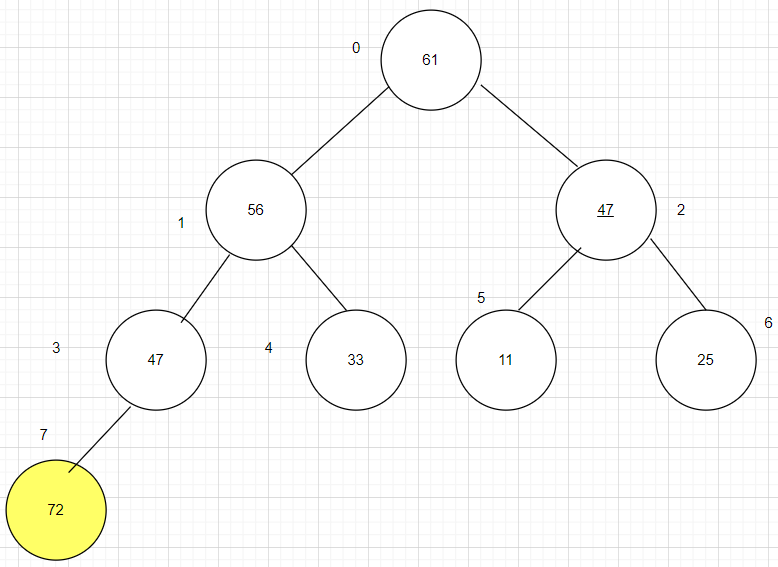
第三步:将根结点(最大值)与最后一个结点调换,完成第一趟排序,第一趟排序的结果为。47 56 61 47 33 11 25 [72] 这样最大的数就在最后了
第四步:重新调整为堆,从上到下开始,逐渐将最大的替换到根结点
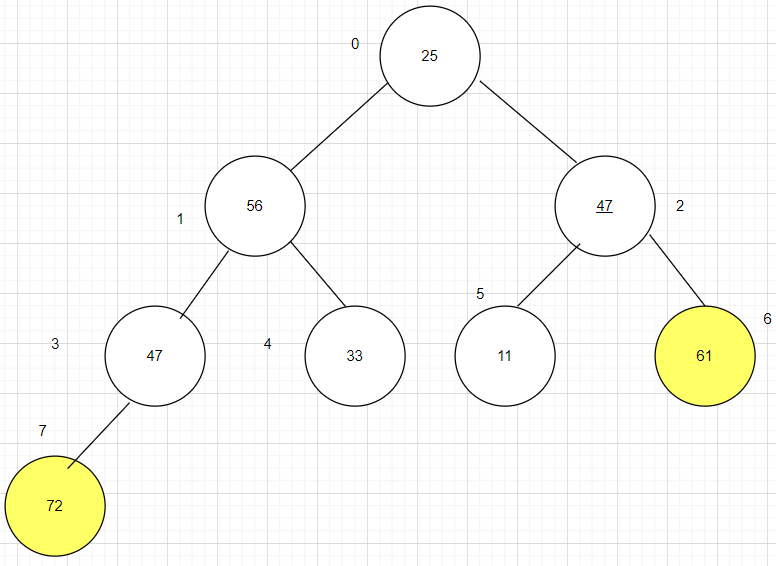
第五步:将第一趟排序的结果除最后一个元素外的其余结点组成的序列调整为堆,然后将根结点与倒数第2个结点调换,完成第二趟排序,第二趟结果为:25 56 47 47 33 11 25 [61 72]
二叉树是从左到右,从上到下开始,所以第三层最后一个是25,所以替换25
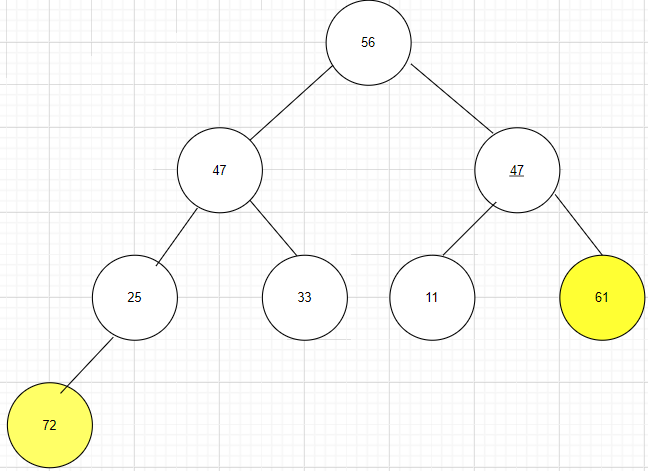
第六步:重新调整为堆
第七步:将第一趟排序的结果除最后一个元素外的其余结点组成的序列调整为堆,然后将根结点与倒数第3个结点调换,完成第三趟排序,第三趟结果为:11 47 47 25 33 11 [56 61 72]
重复上面步骤
第四趟结果为:11 33 47 25 [47 56 61 72]
第五趟结果为:25 33 11 [47 47 56 61 72]
第六趟结果为:11 25 [33 47 47 56 61 72]
第七趟结果为:11 [25 33 47 47 56 61 72]
算法描述
/*
* 堆排序
* 可以根据完全二叉树性质进行排序
* 假设R[1]为根结点,则
* 任意结点R[i]的左孩子是R[2i]
* 右孩子是R[2i+1]
* 双亲结点R[i / 2]
* 堆排序只需要将R[2i]和R[2i+1]中较大值与该结点的父结点R[i]进行比较,比父结点大则交换
*/
/*
* 交换位置
* array -- 待排序数组
* a -- 根结点
* b -- 待排序的二叉树尾部结点
*/
void swapHeap(int array[], int a, int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}
/*
*构建大根堆
* array -- 待排序数组
* i -- 用于确定完全二叉树左右子树:假设根结点:array[i],左子树:array[2i],右子树:array[2i + 1],双亲结点:array[i / 2]
* length -- 数组长度
*/
void adjustHeap(int array[], int i, int lenght) {
int temp = array[i];
for (int k = i * 2 + 1; k < lenght; k = k * 2 + 1) //从i结点的左子结点开始,也就是2i+1处开始
{
if (k + 1 < lenght && array[k] < array[k + 1]) { //用于获取左右子结点中最大的,如果左子结点小于右子结点,k指向右子结点
k++;
}
if (array[k] > temp) { //如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)
array[i] = array[k];
i = k;
}
else {
break;
}
}
array[i] = temp; //将temp值放到最终的位置
}
/*
*初始化堆
* 从上往下 只要保证第0元素是最大的
* array -- 待排序数组
* size -- 数组大小
*/
void HeapSort(int array[], int size) {
//初始构建大根堆
for (int i = size / 2; i >= 0; i--)
{
adjustHeap(array, i, size);
}
//该步骤,由于之前已经建立大根堆,也就是父结点基本大于子结点
for (int j = size - 1; j > 0; j--) {
swapHeap(array, 0, j);//将堆顶元素与末尾元素进行交换
adjustHeap(array, 0, j);//重新对堆进行调整
}
}
算法分析
时间复杂度
其中构建初始堆经推导复杂度为O(n),在交换并重建堆的过程中,需交换n-1次,而重建堆的过程中,根据完全二叉树的性质,[log2(n-1),log2(n-2)...1]逐步递减,近似为nlogn。所以堆排序时间复杂度一般认为就是O(nlogn)级。
(4)稳定性
堆排序是不稳定的。