
二叉树的存储结构
顺序存储结构
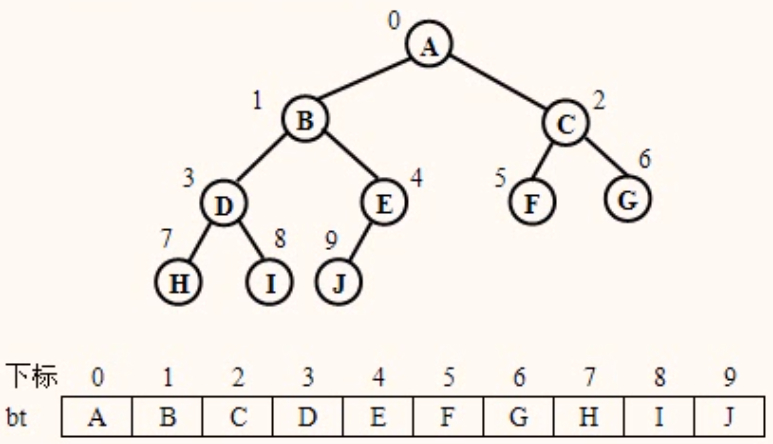
完全二叉树的顺序存储结构
性质五修改为:
如果将一棵有n个结点的完全二叉树按层从0开始编号,则对任一编号为i(0 ≤ i < n)的结点X有:
若i=0,则结点X是根;若i>0,则x的双亲的编号为[(i-1)/2]
若2i+1 < n,则结点X的左孩子编号为2i+1,否则,结点X无左孩子(且无右孩子),必定为叶子结点
若2i+2 < n,则结点X的右孩子的编号为2i+2,否则x无右孩子。
一般二叉树的顺序存储
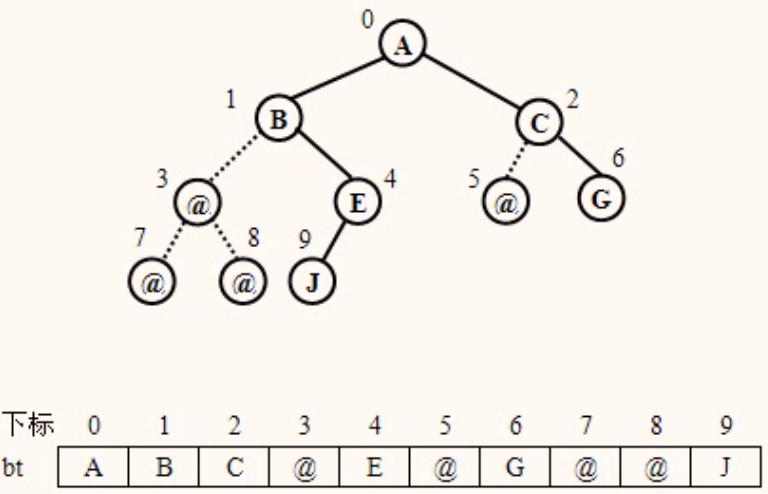
顺序存储二叉树的优点和缺点
- ①对完全二叉树而言,顺序存储结构既简单又节省存储空间。
- ②一般的二叉树采用顺序存储结构时,虽然简单,但易造成存储空间的浪费。最坏的情况下,一个深度为k且只有k个结点的右单支树需要2k-1个结点的存储空间(相当于满二叉树)。
- ③在对顺序存储的二叉树做插入和删除结点操作时,要大量移动结点。
链式存储结构
二叉链结点结构
| lchild | data | rchild |
说明:
- ①数据域data,用以存放元素值。
- ②指针域lchild和rchild,分别指向该结点的左孩子和右孩子。没有左孩子时lchild=NULL,没有右孩子时rchild=NULL,

二叉链结点类型定义
typedef struct node
{
DataType data;
Struct node *lchild,*rchild; //左右孩子指针
}BinTNode; //结点类型
typedef BinTNode *BinTree; //BinTree为指向BinTNode类型结点的指针类型
三叉链结点结构
| lchild | data | parent | rchild |
说明: 增加的parent域指向其双亲

二叉树的运算
二叉树的生成
按广义表
按广义表表示二叉树结构生成二叉链表的算法

算法中用了一个指针数组来模拟栈存储结点的双亲指针,根据读入广义表中的字符分四种不同的情况进行处理:
算法描述
BinTNode * CreateTree(char * str)
{
//str为存储广义表的字符串的指针
BinTNode *st[100]; //用指针数组模拟栈
BinTNode *p=NULL;
int top,k,j=0;
top= -1; //置空栈
char ch=str[j]; //存放广义表的字符串的数组
BinTNode *b=NULL;
while(ch!='\0') //循环读广义表字符串中字符
{
switch(ch)
{
case '(':
top+t; st[top]=p; k=1; //左括号表示新的子树的开始,所以刚建立的结点指针入栈
break;
case ')' :
top--; //右括号表示一个子树的结束,栈顶元素没有子树,出栈
break;
case ',':
k=2;
break;
default:
p=(BinTNode*)malloc(sizeof(BinTNode)); //读到的是字符
p->data=ch; //填写数据域
p->lchild=p->rchild=NULL; //填写指针域
if(b==NULL) //建立第一个结点
{
b=p;
}
else {
switch(k)
{
case 1:
st[top]->lchild=p; //前一个字符是'(',该结点应该插入到左子树
break;
case 2:
st[top]->rchild=p; //前一个字符是')',该结点应该插入到右子树
break;
}
}
}
j++;ch=str[j]; //读取下一个字符
}
return b; //返回根结点的指针
}
按完全二叉树
按完全二叉树的层次顺序依次输入结点信息建立二叉链表的算法
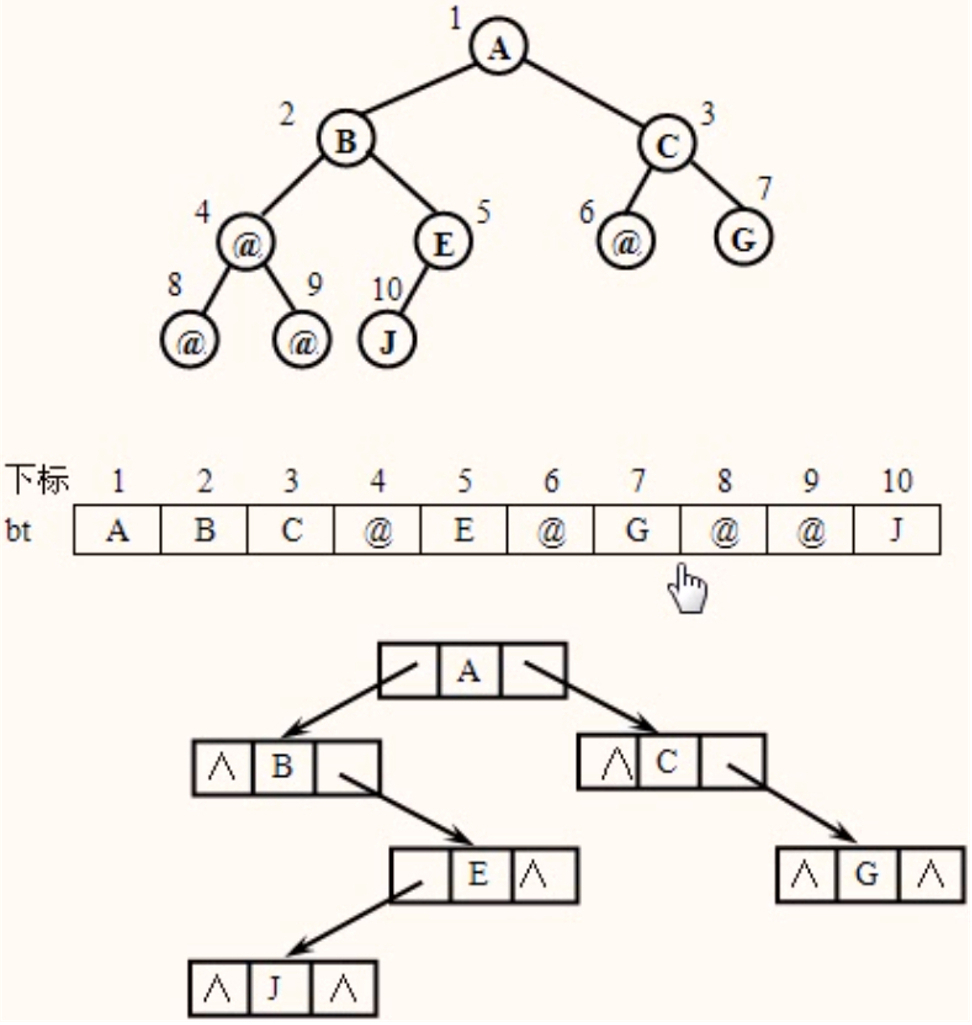
算法思想
首先对一般的二叉树添加若干个虚结点,使其成为完全二叉树,然后依次输入结点信息,若输入的结点不是虚结点"@",则建立一个新结点,若是第一个结点,则令其为根结点,否则将新结点作为左孩子或右孩子链接到它的双亲结点上。如此重复下去,直到输入结束符号"#"时为止(假设结点数据域为字符型)。
为了使新结点能正确地链接到其双亲结点,可设置一个指针数组作为队列,保存已输入的结点地址。因为是按层自左向右输入结点,所以先输入的结点的孩子结点先入队列,可以利用队列的队头指针front指向当前结点的双亲结点,利用队尾指针rear指向当前结点。若rear为偶数,则说明当前结点应作为左孩子链接到front所指向的结点上;否则,当前结点应作为右孩子链接到front所指向的结点上,链接后,使队头指针front指向下一个双亲结点。若当前结点为虚结点,则无需链接
算法描述
BinTree CreateBinTree (BinTree bt)
{
//Q[1. . n]是一个BinNode类型的指针数组,front和rear分别是队头和队尾指针
BinTNode *Q[100]; //定义队列
BinTNode *s;
int front,rear;
char ch;
ch=getchar();
bt=NULL; //置空二叉树
front=1; rear=O; //初始化队列
while(ch!='#') //假设结点值为单字符,#为终止符。
{
s=NULL; //先假设读入的为虚结点"@"
if(ch!='@')
{
s=(BinTNode* )malloc(sizeof(BinTNode)); //申请新结点
s->data=ch;
s->lchlid=s->rchiId=NULL; //新结点赋值
}
rear++; //队尾指针自增
Q[rear]=s; //将新结点地址或虚结点地址(NULL)入队
if(rear==1) //若rear为1,则说明是根结点,用bt指向
bt=s;
else
{
if(s!=NULL&&Q[front] !=NULL) //当前结点及其双亲结点都不是虚结点
{
if(rear%2==0) //rear为偶数,新结点应作为左孩子
Q[front]->lchild=s;
e1se
Q[front]->rchild=s; //rear为奇数,新结点应作为右孩子
if(rear%2!=0)
frontt+; //rear为奇数,说明front所指结点的左右儿子都处理完了,因此front加1指向下一个双亲
}
}
ch=getchar(); //读下一个结点值
}
return bt;
}
二叉树的遍历
遍历: 是指沿着某条搜索路径(线)周游二叉树,依次对树中每个结点访问且仅访问一次。
遍历方案
从二叉树的递归定义可知,一棵非空的二叉树由根结点及左、右子树这三个基本部分组成。因此,在任一给定结点上,可以按某种次序执行三个操作:
- ①访问根结点本身(D),
- ②遍历根结点的左子树(L),
- ③遍历根结点的右子树(R)。
以上三种操作有六种执行次序:
DLR(根左右)、LDR(左根右)、LRD(左右根);
DRL(根右左)、RDL(右根左)、RLD(右左根)。
注意: 前三种次序(按先左后右)与后三种次序(按先右后左)对称,故只讨论先左后右的前三种次序。
递归遍历算法
三种遍历的递归定义:
(1)先序遍历DLR(根左右): 也叫先根遍历,若二叉树非空,则依次执行如下操作:
- ①访问根结点;
- ②遍历左子树;
- ③遍历右子树。
(2)中序遍历LDR(左根右): 也叫中根遍历,若二叉树非空,则依次执行如下操作:
- ①遍历左子树;
- ②访问根结点;
- ③遍历右子树。
(3)后序遍历LRD(左右根): 也叫后根遍历,若二叉树非空,则依次执行如下操作:
- ①遍历左子树;
- ②遍历右子树;
- ③访间根结点。
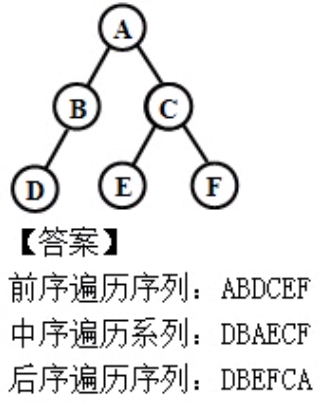
例题1
分别写出图所示的二叉树的前序、中序、后序遍历序列。
例题2
假设二叉树的RNL遍历算法定义如下:
若二叉树非空,则依次执行如下操作:
(1)遍历右子树;
(2)访问根节点;
(3)遍历左子树。
已知一棵二叉树如图所示,请给出其RNL遍历的结果序列。
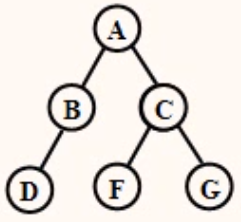
解析:
根据二叉树的RNL(右根左)遍历算法定义和我们已经研究过的LNR(左根右)遍历算法定义,可以写出该二叉树的RNL(右根左)遍历的结果序列:GCFABD;二叉树的LNR(左根右)遍历的结果序列:DBAFCG;二者是对称的。
三种遍历算法
(1)前序遍历递归算法:
void Preorder(BinTree bt)
{
//采用二叉链表存储结构,并设结点值为字符型
if(bt!=NULL)
{
printf("%c",bt->data); //访问根结点
Preorder(bt->lchild); //前序遍历左子树
preorder(bt->rchild); //前序遍历右子树
}
}
(2)中序遍历递归算法:
void Inorder(BinTree bt)
{
if(bt!=NULL)
{
Inorder(bt->lchild); //中序遍历左子树
printf("%c",bt->data); //访问根结点
Inorder(bt->rchild); //中序遍历右子树
}
(3)后序遍历递归算法:
void Postorder(BinTree bt)
{
if(bt!=NULL)
{
Postorder(bt->lchild); //中序遍历左子树
Postorder(bt->rchild); //中序遍历右子树
printf("%c",bt->data); //访问根结点
}
递归算法描述
为便于理解递归算法,以下图(二叉树和二叉链表)为例,说明上面算法Preorder遍历二叉树的执行过程
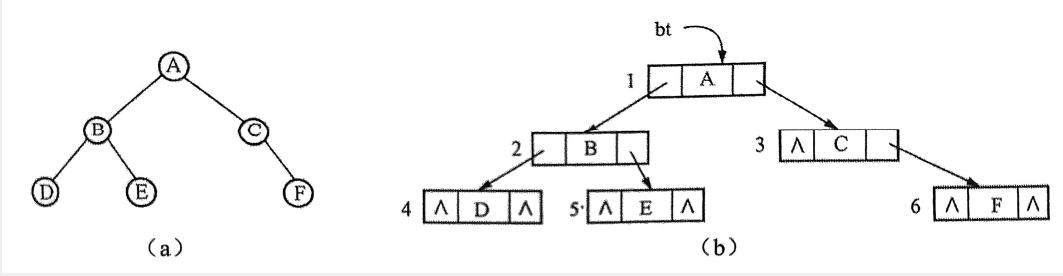
前序遍历二叉树算法的执行过程示意图:
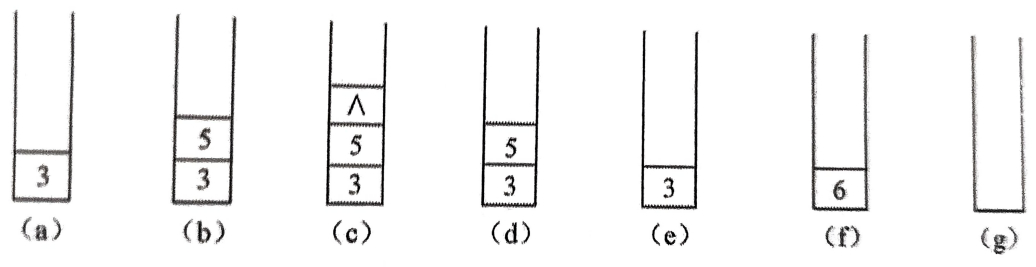
过程
二叉链表左边序号假设为该结点的存储地址
当一个函数调用前序遍历算法时,首先需要以指向二叉树根结点的地址1作为实参,将它传递到算法中的形参bt,然后执行算法。在算法执行过程中,总是先前序遍历左子树,此时的右子树并没有得到及时的遍历,所以要记住此时右子树的访问结点,等左子树遍历结束后再回来遍历右子树,因此需要一个工作栈来存储右子树bt->child的访问结点
假定该工作栈为S,当一开始调用函数时,由于bt不为NULL,访问根结点,输出A,递归调用前序遍历左子树bt=2,此时右子树的地址3存入S中,如图(a)所示,bt=2不为NULL,访问bt指向的结点,输出B,再递归调用,bt=4,右子树的地址5存入S中,如图(b)所示。此时的左子树bt不为NULL,访问bt指向的结点,输出D,此时左子树为空,右子树也为空,回溯到上一层,遍历2的右子树5,输出E,因为5的左右子树均为空,退栈,遍历1的右子树3,输出C,左子树空,再遍历右子树,输出F,这时左右子树均为空,遍历结束
访问结点次序为:ABDECF
二叉树遍历的非递归算法
由中序遍历递归算法的执行过程可知,递归工作栈包括两项:一项是递归调用的语句编号;另一项是指向根结点的指针
当栈顶记录中的指针值为非空时,应该遍历左子树,即指向左子树根结点的指针进栈。否则当栈顶记录中的指针值为空时,则应该退回到上一层,此时若是从左子树返回,则应该访问当前栈顶记录中指针所指向的根结点;若是从右子树返回,则说明当前层已遍历结束,继续退栈
(1)利用栈的非递归中序遍历算法:
void Inorder1(BinTree bt)
{
// 采用二叉链表存储结构
SeqStack S; BinTNode *P;
InitStack(&S);
Push(&S,bt); //根结点入栈
while(!StackEmpty(&S))
{
while(GetTop(&S)) //读栈顶元素,当栈顶不为空
{
Push(&S,GetTop (&S)->lchild); //左孩子依次入栈,直到左子树空为止
}
p=Pop(&S); //最后一个入栈的空指针退栈
if(!StackEmpty(&S))
{
printf("%c",GetTop(&S)->data); //访问根结点
p=Pop(&S);
Push(&s,p->rchild); //右子树进栈
}
}
(2)利用指针数组模拟栈实现的非递归中序遍历算法:
void Inorder2(BinTree bt)
{
//二叉树非递归中序遍历算法
BinTNode *ST[100]; //用指针数组模拟栈
int top=0; //初始化数组
ST[top]=bt;
do {
while(ST[top] !=NULL) //根结点及其所有的左结点地址装入数
{
top=top+1;
ST[top]=ST[top-1]->lchild;
}
top=top-1; //最后一个入数组的空指针退"栈”
if(top>=0) //判数组中地址是否访问完
{
printf("%c",ST[top]->data); //访问结点
ST[top]=ST[top]->rchild; //扫描右子树
}
}while(top!=-1);
}
(3)利用栈的非递归前序遍历算法:
算法思想: 利用栈先将二叉树根结点指针入栈,然后执行出栈,获取栈顶元素值(即结点指针),若不为空值,则访问该结点,再将右、左子树的根结点指针分别入栈,依次重复出栈、入栈,直至栈空为止。
void Preorder1(BinTree bt)
{
SeqStack S;
InitStack(&S); //初始化栈
Push(&s, bt); //根结点指针进栈
while(!StackEmpty(&S))
{
bt=Pop (&S); //出栈
if(bt !=NULL)
{
printf("%c",bt->data); //访问结点,假设数据域为字符型
Push(&S,bt->rchild); //右子树入栈先访问左子树,栈先进后出
Push(&S,bt->lchiid); //左子树入栈
}
}
(4)非递归的按层遍历二叉链表树:
按层遍历二叉树:从上到下,从左到右遍历二叉树。
例:
对下图二叉树按层进行遍历
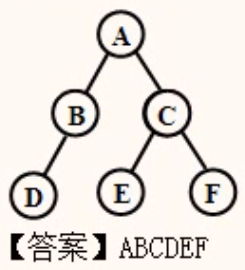
算法思想
采用一队列Q,若树不空,先将二叉树根结点输出,并将根结点指针入队,然后出队。若根结点有左子树,则将左子树的根结点输出并将其指针入队﹔若其有右子树,则将其右子树的根结点输出并将其指针入队,再出队,如此下去,直至队列空为止。
算法描述:
void TransLevel(BinTree bt)
{
cirQueue Q; //按层遍历二叉树,从上到下,从左到右
InitQueue(&Q); //初始化队列为空队列
if(bt==NULL)
return;
else{
printf("%c",bt->data); //输出根结点,假设其数据域为字符型
EnQueue(&Q,bt); //根结点指针入队
while(!QueueEmpty(&Q))
{
bt=DeQueue(&Q); //出队列
if(bt->lchild!=NULL)
{
printf("%c",bt->lchild->data); //输出左子树根结点
EnQueue(&Q,bt->lchild); //左子树入队
}
if(bt->rchild!=NULL)
{
printf("%c",bt->rchild->data); //输出右子树根结点
EnQueue(8Q,bt->rchild); //右子树入队列
}
}
}
}
由遍历序列恢复二叉树
已知二叉树的前序遍历序列和中序遍历序列,可以唯一地恢复该二叉树。
原则: 在前序序列中确定根结点〈最前面那个结点一定是根结点〕,然后根据根结点在中序序列中的位置分出根结点的左、右子树(根结点前面的那些结点为根结点的左子树上的结点,根结点后面的那些结点为根结点的右子树上的结点)。恢复该二叉树的任何一棵子树的过程仍然遵循这个原则。
例1
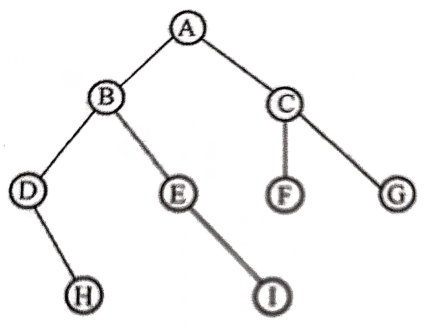
如下图二叉树,写出前、中、后序遍历序列
解析
前序序列:ABDHEICFG
中序序列:DHBEIAFCG
后序序列:HDIEBFGCA
例2
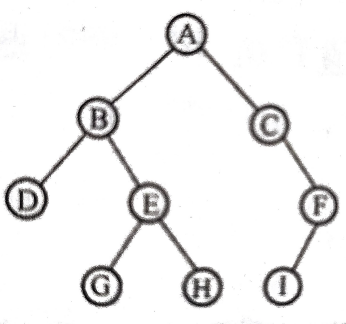
已知二叉树的前序和中序遍历序列或中序和后序遍历序列,求其二叉树
前序序列:ABDEGHCFI
中序序列:DBGEHACIF
分析:
根据二叉树的三种遍历算法可以得出这样一个结论:已知一个二叉树的前序和中序遍历或中序和后序遍历序列,可以唯一地确定一颗二叉树。具体方法如下:
(1)根据前序或后序遍历序列确定二叉树的各子树的根;
(2)根据中序遍历确定各子树根的左、右子树
求解过程
(1)由前序遍历序列确定二叉树的根为A,再由中序遍历确定A的左、右子树
A BDEGH CFI //前序遍历序列的根、左子树和右子树
BDEGH A CIF //中序遍历序列的左子树、根和右子树
(2)确定A的左子树
B D EGH //前序遍历左子树的根、左子树和右子树
D B GEH //中序遍历左子树、根和右子树
(3)再确定B的右子树
由前序序列EGH和中序序列GEH唯一确定E为根,G、H分别为左子树和右子树
E G H //前序遍历左子树的根、左子树和右子树
G E H //前序遍历左子树、根和右子树
(4)确定A的右子树
C FI //前序遍历A右子树的根和右子树
C IF //中序遍历A右子树的根和右子树
(5)再确定C的右子树。
由前序FI和中序IF确定F为根,I为左子树
F I //前序遍历C左子树的根和左子树
I F //中序遍历C左子树的根和左子树
由此可得该二叉树的后序遍历序列为:DGHEBIFCA
例3
已知一棵二叉树的前序遍历序列与中序遍历序列分别为:
前序遍历序列:A B C D E F G H I
中序遍历序列:B C A E D G H F I
试恢复该二叉树。
解析
【解答】按照上述分解原则求得整棵二叉树的过程如所示。
同理,已知二叉树的中序遍历序列和后序遍历序列,也可以唯一地恢复该二叉树,只是在后序序列中去确定根结点〈最后面那个结点一定是根结点),而在中序序列中分出左右子树的过程与上述过程没有区别。
已知二叉树的前序遍历序列和后序遍历序列,无法唯一地恢复该二叉树,因为无法确定左右子树。
